GIS Class - Mike McAdams
Challenges and Solutions
Introduction
The challenges of this analysis revolved around the data. Some of the problems involved the
accuracy and precision of the data while the other problems stemmed from the lack of obtainable data.
As discussed earlier the forest data is in a grid of 1000 m by 1000 m cells. Buffer zones for
streams and roads range from 30 to 300 feet (9.1 to 91.4 m). The combination of these two caused a
problem. In order to remove the area around roads and rivers in the 1000 m forest data the buffer
zone would have to be on the order of 500 m. Because the buffer zones are small, removal is not
possible with this configuration.
A possible solution to this problem was to either re-sample the data sets on the 100 m cell scale or
download new data sets that were at the 100 m cell scale. This option would have increased file size
and analysis time by a factor of 100. This option was not chosen, but instead the decision was made
to refine the analysis area to a singular 30 second by 30 second area. This new smaller area would
make it possible to obtain more realistic data at a realistic file size and computer time.
Comparisons of the original and refined data sets are shown below. New data was downloaded and
forest data was re-sampled.
Results
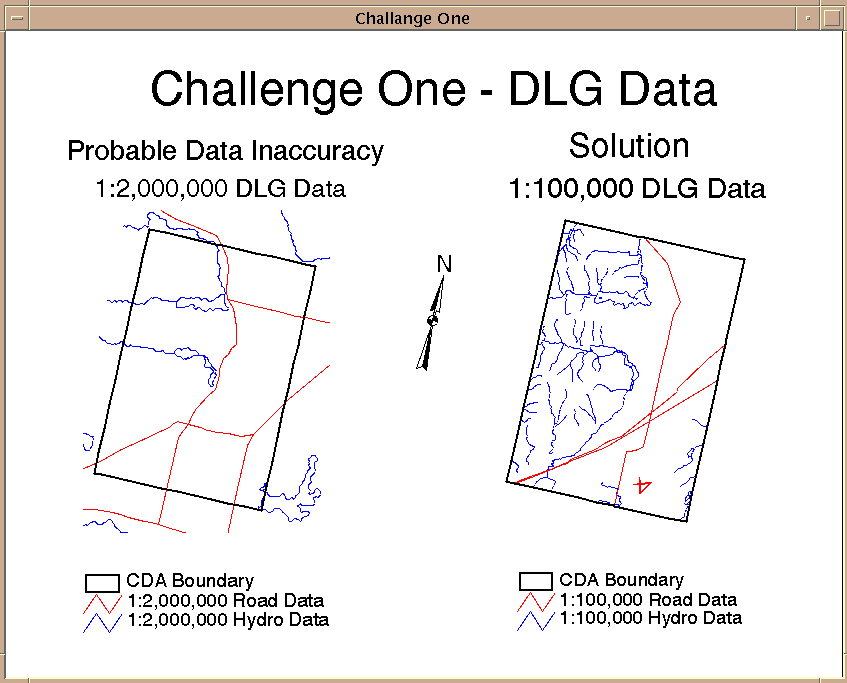
|
Data Challenge - Buffer Zones |
The picture above compares the original 1:2,000,000 road and hydrology data set (on the left) to the
1:100,000 road and hydrology on the right.
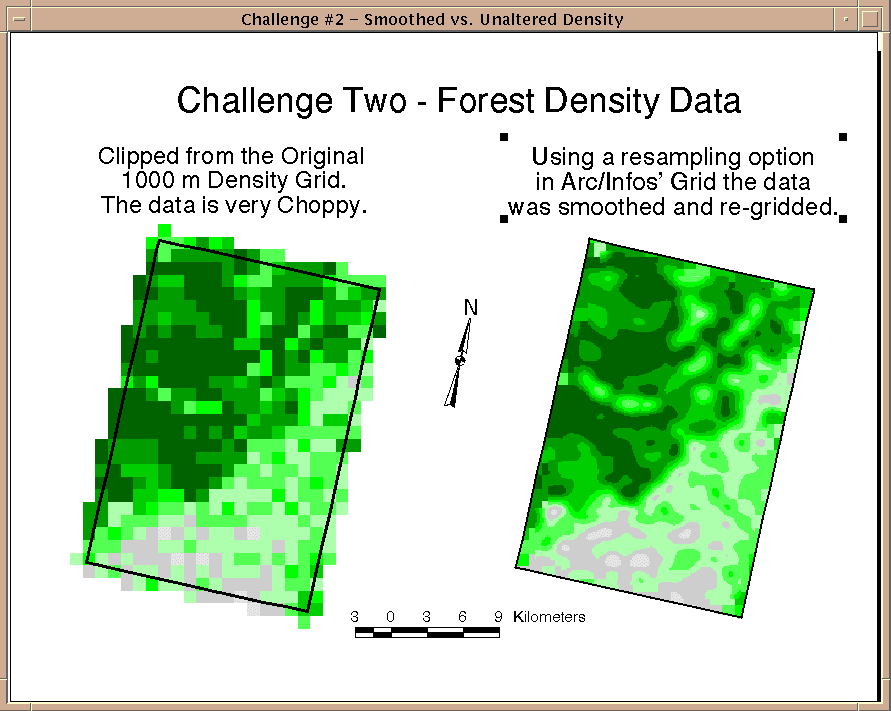
|
Data Challenge - Cell Size |
Above the 1000 m cell size forest density on the left and the re-sampled (and smoothed) 100 m cell
size on the right.
A new DEM (1:250,000 scale) was used for the refined area. This allowed for a more realistic
estimate of slope. Unfortunately, the slopes in this area were found to be lower than 45%
(the threshold value for conventional logging). This can be attributed to two possible causes.
Either slopes in this area are in fact shallower than other parts of the state or the DEM used is
still not fine enough to correctly characterize the actual slope features. It was then decided,
for exercise purposes only, to exclude slopes from the forest analysis greater than 30% grade.
Obtaining data was also a stumbling block. Boundary data on national and state parks, Indian
reservations, wilderness areas, private and municipal land holdings and recently cut forest
regions were not included in the analysis. It is entirely possible that these areas could
significantly decrease the land available for analysis. This is the area where future work could
provide some of the greatest benefit to analyses accuracy.
Go to Mike's GIS Page
Go to Mike's Home Page
Go to Civil Engineering Home Page
Go to UT's Home Page
(c) Copyright Mike McAdams, 1997
if you want something e-mail me at:
mcadams@mail.utexas.edu