Utiliser un modèle pour simuler un écoulement de surface à partir d'une carte dans le bassin du Niger en Afrique de l'Ouest, et présenter quelques outils d'analyse graphique disponibles avec ce modèle. Les paramètres d'entrée (précipitations et ruissellement) pour la calibration du modèle ont déjà été préparés pour cette région et fournissent des résultats raisonnables.
Cet exercice nécessite l'utilisation d'Arcview Version 2.0 ou supérieure. Les données dont vous avez besoin pour cet exercice ont déjà été rentrées dans les PC que vous allez utiliser. Vous pouvez les trouver dans le répertoire \gisfiles\ex4af\ngflow.
Pour commencer, lancez ArcView et ouvrez le projet appelé ngflow.apr . Ouvrez la vue Niger et vous verrez une carte où les cours d'eau sont représentés par des lignes et les bassins de drainage utilisés dans le modèle par des polygones. Vous devez voir huit thèmes dans la vue Niger. Une brève description de ces thèmes est donnée ci-dessous :
Une simulation basée sur 90 mois de données, de juillet 1983 à décembre 1990, a déjà été réalisée. La première partie de cet exercice va vous montrer comment observer certains des paramètres d'entrée et de sortie de cette simulation. Vous allez ensuite définir (en le découpant) un sous-modèle de dimension inférieure, pour lequel vous allez effectuer une simulation et utiliser une procédure d'optimisation. Vous n'aurez ainsi pas à utiliser la simulation pour le bassin en entier, ce qui prend un certain temps...
Les valeurs du surplus sont les paramètres d'entrée du
modèle de simulation d'écoulement de surface. Le surplus
est l'excès de pluie qui est disponible pour la génération
d'un écoulement. Les valeurs de surplus utilisées ici résultent
du calcul de bilans pour l'eau du sol. Un tableau contenant des séries
de 90 valeurs de surplus en fonction du temps pour chaque sous-bassin sur
la carte est disponible. Pour construire un graphe donnant la variation
en fonction du temps du surplus dans le bassin de drainage de votre choix,
cliquez sur ![]() . Dans le premier
menu, tapez 1 pour indiquer que vous souhaitez représenter
une série de données à un endroit de la carte. Cliquez
sur OK puis sur n'importe quel sous-bassin de la carte. Remarque : Les
bassins dans le tiers inférieur de la carte reçoivent beaucoup
plus de pluie que les bassins situés vers le haut de la carte. Si
vous cliquez sur un bassin près du sommet de la carte, vous ne verrez
que peu ou pas de surplus. Dans le menu suivant, sélectionnez
"psurp.dbf" comme tableau à représenter et cliquez
sur OK. Cliquez sur YES pour conserver le graphe puis sur OK pour lui donner
un nom par défaut. On vous demandera si vous voulez ou non représenter
graphiquement des données d'un autre tableau pour le même
emplacement. Cliquez sur NO. Cliquez sur un autre emplacement sur la carte.
Choisissez de nouveau "psurb.dbf" comme tableau pour la construction
graphique. Cliquez sur OK, conservez le graphe (YES), donnez-lui un nom
(OK), et cliquez sur NO lorsqu'on vous demandera si vous voulez représenter
un autre tableau.
. Dans le premier
menu, tapez 1 pour indiquer que vous souhaitez représenter
une série de données à un endroit de la carte. Cliquez
sur OK puis sur n'importe quel sous-bassin de la carte. Remarque : Les
bassins dans le tiers inférieur de la carte reçoivent beaucoup
plus de pluie que les bassins situés vers le haut de la carte. Si
vous cliquez sur un bassin près du sommet de la carte, vous ne verrez
que peu ou pas de surplus. Dans le menu suivant, sélectionnez
"psurp.dbf" comme tableau à représenter et cliquez
sur OK. Cliquez sur YES pour conserver le graphe puis sur OK pour lui donner
un nom par défaut. On vous demandera si vous voulez ou non représenter
graphiquement des données d'un autre tableau pour le même
emplacement. Cliquez sur NO. Cliquez sur un autre emplacement sur la carte.
Choisissez de nouveau "psurb.dbf" comme tableau pour la construction
graphique. Cliquez sur OK, conservez le graphe (YES), donnez-lui un nom
(OK), et cliquez sur NO lorsqu'on vous demandera si vous voulez représenter
un autre tableau.
Vous pouvez également représenter graphiquement les variations par rapport au temps des débits simulés au "to-node" (point situé à la frontière amont d'un bassin particulier), et au "from-node" (point situé à la frontière aval d'un bassin particulier). La procédure utilisée est essentiellement la même que celle décrite ci-dessus. Des graphes de ce type peuvent être utilisés pour constater que certains des bassins sont "gagnants" (gaining reach) et d'autres "perdants" (losing reach). Voici une procédure que vous pouvez suivre pour observer les débits en amont et en aval de deux bassins de ce type. Une image a été insérée ici pour vous aider à localiser ces deux bassins. Le bassin ayant le "grid-code" 448 est un bassin "gagnant" et celui ayant le "grid-code" 1969 est un bassin "perdant".

Cliquez sur ![]() , choisissez l'option
1 , et cliquez sur OK. Cliquez sur le sous-bassin 448. Sélectionnez
"fflow.dbf", et cliquez sur OK. Conservez le graphe en cliquant
sur YES. Cliquez sur OK pour le nom du graphe, puis sur YES pour utiliser
un nouveau tableau de données. Sélectionnez "tflow.dbf"
et cliquez sur OK, puis sur YES et sur OK, et enfin sur NO. Il peut être
utile de modifier la taille des fenêtres des graphiques avec la souris
de façon à observer plus facilement les résultats.
En regardant ces résultats, il apparaît clairement qu'il s'agit
d'un bassin "gagnant" parce que les valeurs en aval (tflow) sont
plus élevées que les valeurs en amont (fflow). Faites attention
lorsque vous observez ces graphiques parce que les échelles des
x sont automatiquement modifiées pour refléter l'intervalle
des valeurs. Sur l'axe des x, "J" représente juillet et
"D" décembre. Recommencez la même procédure
pour observer les graphiques du bassin ayant le "grid-code" 1969
et vous verrez qu'il s'agit d'un bassin "perdant".
, choisissez l'option
1 , et cliquez sur OK. Cliquez sur le sous-bassin 448. Sélectionnez
"fflow.dbf", et cliquez sur OK. Conservez le graphe en cliquant
sur YES. Cliquez sur OK pour le nom du graphe, puis sur YES pour utiliser
un nouveau tableau de données. Sélectionnez "tflow.dbf"
et cliquez sur OK, puis sur YES et sur OK, et enfin sur NO. Il peut être
utile de modifier la taille des fenêtres des graphiques avec la souris
de façon à observer plus facilement les résultats.
En regardant ces résultats, il apparaît clairement qu'il s'agit
d'un bassin "gagnant" parce que les valeurs en aval (tflow) sont
plus élevées que les valeurs en amont (fflow). Faites attention
lorsque vous observez ces graphiques parce que les échelles des
x sont automatiquement modifiées pour refléter l'intervalle
des valeurs. Sur l'axe des x, "J" représente juillet et
"D" décembre. Recommencez la même procédure
pour observer les graphiques du bassin ayant le "grid-code" 1969
et vous verrez qu'il s'agit d'un bassin "perdant".
Pour présenter les possibilités de simulation et d'optimisation du modèle il est plus facile, pour accélérer les calculs, de définir un sous-modèle à partir du modèle entier. Pour créer un sous-modéle utilisable,

Vous ne pouvez pas voir le point représentant la station de Koulikoro sur cette carte parce qu'il se trouve dans la zone sélectionnée. Dès que vous avez effectué votre sélection, assurez-vous que les thèmes "Mrunoff," "Dams.shp," "Flowchk.shp," "Ngriver.shp," et "Ngbasin.ply" sont toujours les thèmes actifs.
Vous avez probablement envie d'agrandir la vue (View1) contenant le sous-modèle. Elle ressemble à peu près à cela :

Fermez la vue "Niger" dont vous n'aurez plus besoin dans le reste de cet exercice. Pour lancer le modèle de simulation, assurez-vous que la vue contenant votre sous-modèle est active et choisissez l'option SFwModel/SFlowSim dans les menus. Vous aurez alors la possibilité de spécifier certains paramètres de la simulation. Voici une description des paramètres se trouvant dans ce menu :
Ne modifiez pas ces paramètres et cliquez sur OK pour lancer la simulation. Vous verrez les arcs du fleuve être sélectionnés pendant les calculs.
Les étapes de base de l'algorithme consiste à convertir les données de surplus pour chaque bassin en une contribution locale au débit (Pflow). Cette opération s'effectue au moyen d'une fonction réponse. Plusieurs options sont disponibles dans le programme pour calculer la progression de l'écoulement dans le réseau du fleuve. Parmi ces options, il existe une approche par fonction réponse, la méthode de Muskingum Cunge, et une approche en deux étapes. Le modèle en deux étapes de progression de l'écoulement est un cas particulier du modèle de la fonction réponse. C'est le modèle qui est utilisé par défaut lorsqu'une fonction réponse n'est pas disponible ou lorsque la méthode de Muskingum n'est pas efficace sur le plan calculatoire. L'équation de base pour le modèle en deux étapes est donnée ici :
![]()
Dans cette équation, Llagi est le "retard" normalisé entre le "from-node" et le "to-node" d'un segment i du fleuve. Llagi est défini par :

Dflow est le détournement d'eau, qui est nul dans ce cas. Li
est la longueur du segment i du fleuve, vi est la vitesse d'écoulement
moyenne dans le segment i (m/s), et t est l'intervalle de temps. Regardons
d'où proviennent les nombres utilisés par le programme pour
effectuer ce calcul. Activez le thème Theme Ngriver.shp et cliquez
sur ![]() pour voir les attributs de
Ngriver.shp. Sélectionnez les données ayant le "grid-code"
441. Notez que la "vitesse" est 0.15 m/s, le coefficient de pertes
"LossC" 0.001 (1/km), et la "longueur" 85083 m. Le
coefficient de pertes est 0.001/1000 ou 0.000001 en (1/m). Ces nombres
peuvent être utilisés pour calculer le Llag du segment 441.
L'intervalle de temps pour les calculs est égal au nombre de secondes
dans un mois ou 86400*365/12=2628000. Le LLag est alors 85083/0.15/2628000
= 0.2158. Pour obtenir FFlow(t) et Fflow(t-1), ouvrez le tableau "fflow.dbf"
et observez-le. Déplacez-vous vers la droite jusqu'à ce que
vous trouviez le champ "gc441". Faisons le calcul pour t=90.
Allez jusqu'au bas du tableau "fflow" et regardez la dernière
rangée. Vous devriez voir quelque chose comme :
pour voir les attributs de
Ngriver.shp. Sélectionnez les données ayant le "grid-code"
441. Notez que la "vitesse" est 0.15 m/s, le coefficient de pertes
"LossC" 0.001 (1/km), et la "longueur" 85083 m. Le
coefficient de pertes est 0.001/1000 ou 0.000001 en (1/m). Ces nombres
peuvent être utilisés pour calculer le Llag du segment 441.
L'intervalle de temps pour les calculs est égal au nombre de secondes
dans un mois ou 86400*365/12=2628000. Le LLag est alors 85083/0.15/2628000
= 0.2158. Pour obtenir FFlow(t) et Fflow(t-1), ouvrez le tableau "fflow.dbf"
et observez-le. Déplacez-vous vers la droite jusqu'à ce que
vous trouviez le champ "gc441". Faisons le calcul pour t=90.
Allez jusqu'au bas du tableau "fflow" et regardez la dernière
rangée. Vous devriez voir quelque chose comme :

Remarquez que les valeurs pour Fflow(90)=79.89 m3/s and Fflow(89)=159.19 m3/s. Regardez maintenant "pflow.dbf" pour déterminer la contribution locale au débit pendant le 90ème mois.

Pflow(90)= 5.27 m3/s. Pour estimer Tflow, il faut calculer les pertes. Les pertes dans le segment i sont estimées par Fflow(i,t)*Length(i)*LossC(i) ou 79.89*85083.26*0.000001=6.80. A partir de toutes ces informations, Tflow peut être calculé : Tflow = 159.19*(0.2158)+79.89*(1-0.2158)+5.27-0-6.80 = 95.5 m3/s. Vous pouvez vérifier cette valeur dans le tableau "Tflow.dbf."

La valeur du tableau est 94.03. La différence s'explique principalement par le fait que la précision des nombres dans les tableaux est moins grande que celle des nombres gardés en mémoire par l'ordinateur, et donc que celle des nombres utilisés dans les calculs.
En plus des histogrammes que nous avons observés pour certains
polygones, une autre façon d'observer les résultats est de
tracer un profil longitudinal. Pour faire cela, sélectionnez ![]() ,
entrez 0 et cliquez sur OK. Cliquez sur un des arcs principaux dans
le réseau du fleuve et choisissez NO pour mesurer la distance de
cet arc au point de sortie le plus en aval. Le programme identifie le parcours
de l'arc sélectionné à l'arc le plus loin en aval
et trace alors un graphe montrant le débit mensuel moyen dans chaque
bassin. L'histogramme montre deux valeurs pour chaque bassin, la valeur
du débit en aval (from-node) et en amont (to-node). L'axe des x
portent les numéros d'identification des noeuds aval (from-node
ID). Un exemple est fournit ici pour vous aider à interpréter
ce graphique.
,
entrez 0 et cliquez sur OK. Cliquez sur un des arcs principaux dans
le réseau du fleuve et choisissez NO pour mesurer la distance de
cet arc au point de sortie le plus en aval. Le programme identifie le parcours
de l'arc sélectionné à l'arc le plus loin en aval
et trace alors un graphe montrant le débit mensuel moyen dans chaque
bassin. L'histogramme montre deux valeurs pour chaque bassin, la valeur
du débit en aval (from-node) et en amont (to-node). L'axe des x
portent les numéros d'identification des noeuds aval (from-node
ID). Un exemple est fournit ici pour vous aider à interpréter
ce graphique.

Dans la figure, vous pouvez voir deux barres étiquetées 118. La première représente le débit entrant dans le bassin 1, la seconde le débit sortant du bassin 1 ( "to flow"). La troisième barre montre qu'il existe une discontinuité entre le débit sortant du bassin 1 et le débit entrant dans le bassin 2. Cela est dû à la présence d'affluents. Les valeurs des "from-node" et des "to-node" pour les bassins 2 et 3 indiquent que ces deux bassins ont plus de pertes que de contribution.
Quelques outils supplémentaires sont disponibles pour ajouter
des points où mesurer le débit et des points de détournement
d'eau au modèle. Pour faire ceci, cliquez sur le drapeau rouge ![]() .
Entrez 1 pour ajouter des points de mesure du débit , cliquez
sur OK, et sélectionnez YES pour effectuer votre choix. Cliquez
sur quelques points dans le réseau du fleuve où vous aimeriez
connaître le débit mensuel moyen. Entrez un numero d'identification
(ID) pour chaque point dans la fenêtre de message. Cliquez sur le
drapeau vert
.
Entrez 1 pour ajouter des points de mesure du débit , cliquez
sur OK, et sélectionnez YES pour effectuer votre choix. Cliquez
sur quelques points dans le réseau du fleuve où vous aimeriez
connaître le débit mensuel moyen. Entrez un numero d'identification
(ID) pour chaque point dans la fenêtre de message. Cliquez sur le
drapeau vert ![]() pour calculer les
valeurs interpolées des débits aux points sélectionnés.
Si l'un de vos points n'est pas assez près de la ligne représentant
un cours d'eau, vous obtiendrez un message d'erreur, mais le programme
d'interpolation fonctionnera pour les autres points de votre sélection
qui sont correctement placés. Si vous éprouvez des difficultés
à sélectionner des points proches des cours d'eau, faites
un zoom sur une zone avant de sélectionner les points de mesure.
Le tableau "Attributes of Flowchk.shp" est activé automatiquement
lorsque l'interpolation des débits est terminée. Dans ce
tableau, les champs "Fflow," "IFlow," et "TFlow"
fournissent le débit mensuel moyen entrant dans le bassin du fleuve
où se trouve le point, le débit mensuel moyen interpolé
au point de mesure, et le débit mensuel moyen sortant de ce bassin.
Le champ "pcntage" est égal à la distance du point
aval ("from node") au point de mesure divisée par la longueur
totale du segment contenu dans le bassin. Si vous ne vous souvenez pas
de la correspondance entre les "ID" des points de mesure et leur
emplacement sur la carte, pour identifier un point, sélectionnez
juste les données qui s'y rapportent dans le tableau et le point
correspondant dans la vue View 1 apparaîtra en jaune.
pour calculer les
valeurs interpolées des débits aux points sélectionnés.
Si l'un de vos points n'est pas assez près de la ligne représentant
un cours d'eau, vous obtiendrez un message d'erreur, mais le programme
d'interpolation fonctionnera pour les autres points de votre sélection
qui sont correctement placés. Si vous éprouvez des difficultés
à sélectionner des points proches des cours d'eau, faites
un zoom sur une zone avant de sélectionner les points de mesure.
Le tableau "Attributes of Flowchk.shp" est activé automatiquement
lorsque l'interpolation des débits est terminée. Dans ce
tableau, les champs "Fflow," "IFlow," et "TFlow"
fournissent le débit mensuel moyen entrant dans le bassin du fleuve
où se trouve le point, le débit mensuel moyen interpolé
au point de mesure, et le débit mensuel moyen sortant de ce bassin.
Le champ "pcntage" est égal à la distance du point
aval ("from node") au point de mesure divisée par la longueur
totale du segment contenu dans le bassin. Si vous ne vous souvenez pas
de la correspondance entre les "ID" des points de mesure et leur
emplacement sur la carte, pour identifier un point, sélectionnez
juste les données qui s'y rapportent dans le tableau et le point
correspondant dans la vue View 1 apparaîtra en jaune.
En utilisant les détournements spécifiés ici, vous
pouvez maintenant lancer un calcul pour observer les effets d'un détournement
d'eau. Pour monter la possibilité offerte d'ajouter un détournement
de débit constant au modèle, cliquez à nouveau sur
![]() et, cette fois-ci, entrez 0
pour ajouter un point de détournement et sélectionnez
YES pour commencer une nouvelle sélection. Entrez un détournement
de 50 m3/s pour un point du bassin ayant pour "grid-code"
441 -- choisissez-le de manière à pouvoir observer la façon
dont les nombres dans le tableau "tflow.dbf" pour gc441 et pour
l'intervalle de temps 90 changent, par rapport à ceux de l'exemple
calculé ci-dessus. Voir figure ci-dessous
et, cette fois-ci, entrez 0
pour ajouter un point de détournement et sélectionnez
YES pour commencer une nouvelle sélection. Entrez un détournement
de 50 m3/s pour un point du bassin ayant pour "grid-code"
441 -- choisissez-le de manière à pouvoir observer la façon
dont les nombres dans le tableau "tflow.dbf" pour gc441 et pour
l'intervalle de temps 90 changent, par rapport à ceux de l'exemple
calculé ci-dessus. Voir figure ci-dessous

Pour voir les effets de ce détournement sur les résultats de la simulation, vous devez relancer le modéle de simulation. Pour effectuer une autre simulation, sélectionnez le menu SFwModel/SFlowSim et choisissez tous les paramètres par défaut. Dès que cette simulation est terminée, vous pouvez regarder les effets du détournement sur les calculs en considérant le tableau "tflow.dbf". Le débit aval ("to flow") pour le mois 90 pour le "grid-code" 441 est maintenant seulement 44.03 m3/s, au lieu de 94.03 m3/s comme précédemment. Une autre façon de constater les effets du détournement est d'observer les profils longitudinaux avant et après avoir ajouter le détournement. Vous ne pourrez pas faire une comparaison directe parce que les graphes sont automatiquement remis à jour lorque les tableaux de référence changent. Voici quelques graphes qui montrent les effets d'un détournement de 50 m3/s sur les profils.



Avant de lancer une optimisation, enlevez tous les points de détournement
que vous avez placés dans le modèle. Pour faire cela, cliquez
sur ![]() , entrez 0, cliquez sur OK,
puis sur YES. Ne cliquez sur aucun point dans la vue View1. Un processus
d'optimisation modifiant les paramètres du modèle peut être
lancé pour obtenir des résultats proches des données
observées à la station de Koulikoro. Les paramètres
du modèle qui peuvent être utilisés incluent la fraction
du surplus du bassin allant dans un réservoir souterrain, le temps
de séjour moyen de l'eau dans un réservoir souterrain, la
vitesse de ruissellement, le coefficient de perte pour le ruissellement,
la vitesse d'écoulement du cours d'eau, et le coefficient de perte
du cours d'eau. Dans cet exemple, seule la vitesse d'écoulement
du cours d'eau (V) et le coefficient de perte du cours d'eau (LossC) vont
varier pour satisfaire aux données observées. Le processus
d'optimisation cherche à minimiser la racine carrée de la
moyenne du carrés de l'erreur (root mean squared error (RMSE)) en
faisant varier la vitesse d'écoulement et en faisant tendre la somme
des différences de masse (sum of mass differences (SMD)) vers zéro
en faisant varier le coefficient de perte. Les définitions mathématiques
de ces termes sont :
, entrez 0, cliquez sur OK,
puis sur YES. Ne cliquez sur aucun point dans la vue View1. Un processus
d'optimisation modifiant les paramètres du modèle peut être
lancé pour obtenir des résultats proches des données
observées à la station de Koulikoro. Les paramètres
du modèle qui peuvent être utilisés incluent la fraction
du surplus du bassin allant dans un réservoir souterrain, le temps
de séjour moyen de l'eau dans un réservoir souterrain, la
vitesse de ruissellement, le coefficient de perte pour le ruissellement,
la vitesse d'écoulement du cours d'eau, et le coefficient de perte
du cours d'eau. Dans cet exemple, seule la vitesse d'écoulement
du cours d'eau (V) et le coefficient de perte du cours d'eau (LossC) vont
varier pour satisfaire aux données observées. Le processus
d'optimisation cherche à minimiser la racine carrée de la
moyenne du carrés de l'erreur (root mean squared error (RMSE)) en
faisant varier la vitesse d'écoulement et en faisant tendre la somme
des différences de masse (sum of mass differences (SMD)) vers zéro
en faisant varier le coefficient de perte. Les définitions mathématiques
de ces termes sont :
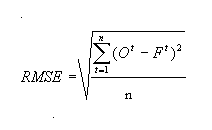


Pour lancer la procédure d'optimisation, activez les thémes
Ngriver.shp, Ngbasin.ply, et Mrunoff et utilisez ![]() pour sélectionner tous les éléments de ces couvertures.
Cliquez sur
pour sélectionner tous les éléments de ces couvertures.
Cliquez sur ![]() . Choisissez Ngriver.shp
comme thème pour lesquels les résultats doivent être
concordants et cliquez sur OK. Une fenêtre intitulée "Location
of gaging station as a fraction of reach length." va apparaître
et une valeur par défaut de 0.814 est donnée. Cliquez juste
sur OK. La valeur 0.814 définit l'emplacement de la station le long
de la ligne représentant le cours d'eau sur lequel elle se trouve,
la mesure s'effectuant à partir de l'extrémité amont.
Vous verrez apparaître le message "Select a control file or
click cancel to create a new control file." Un "control file"
a été préparé pour vous. Cherchez le fichier
c:\ngflow\ex5af.ctl et cliquez sur OK. La fenêtre suivante vous indique
les paramètres qui sont optimisés en utilisant ce "control
file". Ces paramètres sont la vitesse d'écoulement du
cours d'eau et le coefficient de perte du cours d'eau. Les bornes des paramètres
sont spécifiées dans le "control file" pour cet
essai. Les bornes pour la vitesse sont 0.05 m/s et 0.4 m/s, tandis que
celle du paramètre de pertes sont 0.0001 et 0.0015. Cliquez sur
OK, OK, et OK.
. Choisissez Ngriver.shp
comme thème pour lesquels les résultats doivent être
concordants et cliquez sur OK. Une fenêtre intitulée "Location
of gaging station as a fraction of reach length." va apparaître
et une valeur par défaut de 0.814 est donnée. Cliquez juste
sur OK. La valeur 0.814 définit l'emplacement de la station le long
de la ligne représentant le cours d'eau sur lequel elle se trouve,
la mesure s'effectuant à partir de l'extrémité amont.
Vous verrez apparaître le message "Select a control file or
click cancel to create a new control file." Un "control file"
a été préparé pour vous. Cherchez le fichier
c:\ngflow\ex5af.ctl et cliquez sur OK. La fenêtre suivante vous indique
les paramètres qui sont optimisés en utilisant ce "control
file". Ces paramètres sont la vitesse d'écoulement du
cours d'eau et le coefficient de perte du cours d'eau. Les bornes des paramètres
sont spécifiées dans le "control file" pour cet
essai. Les bornes pour la vitesse sont 0.05 m/s et 0.4 m/s, tandis que
celle du paramètre de pertes sont 0.0001 et 0.0015. Cliquez sur
OK, OK, et OK.
Ce processus prend un certain temps. Vous souhaitez sûrement en profiter pour prendre une PAUSE.
Dès que le processus d'optimisation est achevé, cliquez sur OK et vous verrez apparaître quatre graphiques. Le graphe intitulé "massfit.cht" montre les valeurs simulées ("bestmass") et les valeurs observées ("target") pour 90 mois. Le graphe intitulé "mflowfit.cht" montre la même comparaison des 12 valeurs moyennes mensuelles : les simulées ("mflowfit") en fonction des observées ("target"). La notation au sommet de ces graphiques est un peu confuse mais elle peut être expliquée au moyen de la figure suivante.

Ainsi, pour les résultats de cet essai, le processus de modélisation a trouvé qu'une vitesse de 0.203 m/s et un coefficient de perte de 0.00099 (1/km) donnent le meilleur résultat. Les graphes "optmass.cht" et "optrmse.cht" montrent comment SMD et RMSE varient avec le nombre d'itérations. Les valeurs sur l'axe des x représentent le nombre d'itérations et les valeurs sur l'axe des y sont respectivement les SMD et RMSE pour ces itérations.